

Whitepaper: Unlock the value of real-world healthcare data with confidential data clean rooms
As the amount of healthcare data from real-world settings grows, how can care providers and life sciences companies use this data to advance research and treatment while protecting sensitive patient information?

Key takeaways
- Federated learning and confidential computing are not rivals to rank. They fit different situations, and the choice turns on two things: how ready your sites already are, and how much you need to iterate.
- Use federated learning when your participating sites already have harmonized data and the local compute and staff to run it. The path is mature and well understood.
- Use confidential computing (data clean rooms) when you need flexible, iterative analysis, help harmonizing messy data, or you have partners who cannot or will not run local compute. The iCARE4CVD consortium used this approach to cut study setup from about 24 months to about six.
- Neither approach is “fully private.” Federated learning can leak patient data through the model updates it shares, and the standard fix weakens the model. Confidential computing protects data while it is being analyzed but asks you to trust the hardware. The honest tradeoff, not a slogan, should drive the decision.
Why this comparison matters in 2026
Multi-site real-world evidence is having a moment. The European Health Data Space (EHDS), adopted as Regulation (EU) 2025/327, now governs the health data of roughly 450 million people, federated networks like DARWIN EU are expanding, and AI on health data is mainstream. If you lead an RWE program, you are increasingly asked the same architectural question: when you run a study across hospitals or registries, do you use federated learning or confidential computing?
That decision is too often made on a slogan (“the data never moves”) rather than on the tradeoffs that actually affect your timeline, your partners, and your sign-off. This article gives federated learning its strongest case, shows where confidential computing fits better, and lands a decision rule you can defend to your data protection officer (DPO) and your steering committee. Decentriq builds confidential-computing data clean rooms, so that is our approach, but the comparison is only useful if it is honest.
What each approach actually is
- Federated learning trains a model across multiple hospital sites at once. The data stays local; only the model’s mathematical updates move to a central coordinator. The computation goes to the data.
- Confidential computing does the reverse. The data moves, but only under encryption, and it is decrypted only inside sealed hardware memory that no one, including the cloud provider and the platform operator, can read. The data goes to the computation, protected the whole way.
Both differ from the two options your DPO already distrusts. A central data warehouse asks every site to copy raw patient records into one place, which IRBs and DPOs routinely block. A traditional, policy-based clean room relies on contracts and access controls, that is, on promises. Federated learning and confidential computing both replace that promise with a technical guarantee, just in different places: federated learning by never moving the data, confidential computing by keeping it encrypted even during analysis.
How each works in a study
You do not need the cryptography to make the decision, but you do need the shape.
Federated learning
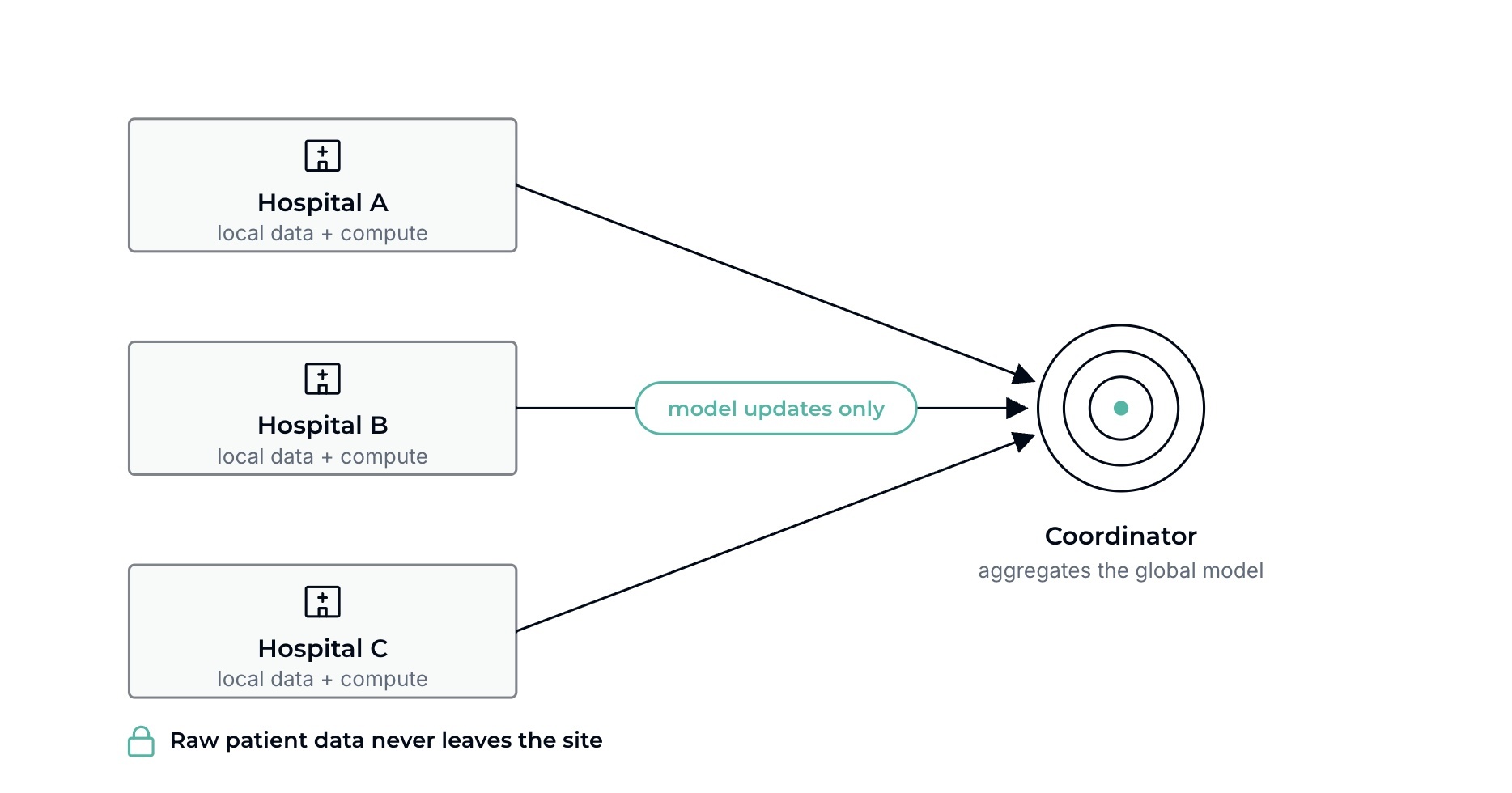
The data never leaves each hospital.
- Each site keeps its own patient data and runs its own compute.
- The coordinator sends out a model; each site trains it locally on its own data.
- Sites send back only the model updates, never raw records.
- The coordinator combines the updates into a better global model and sends it back for the next round.
Confidential computing
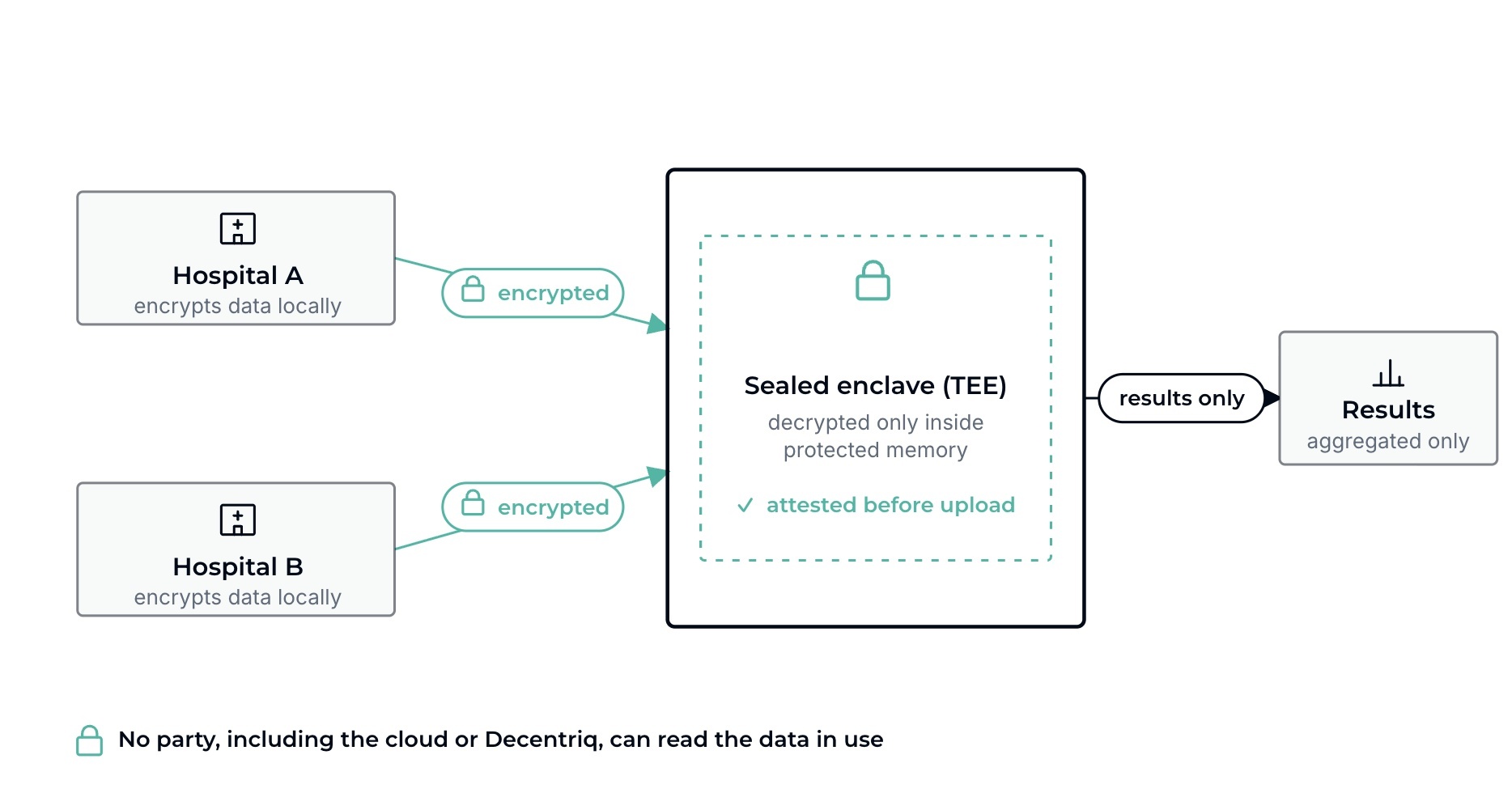
The data moves, but stays encrypted and sealed.
- Each hospital encrypts its data locally, before anything leaves its firewall.
- Before uploading, the hospital’s IT or DPO verifies (through remote attestation) that the environment is genuine hardware running exactly the approved, audited code, and nothing else. Not even Decentriq or the cloud provider can change those rules or read the memory.
- The data is decrypted only inside the sealed enclave, never written to disk in the clear.
- Because raw data is available inside the enclave, researchers can clean, harmonize, explore, and re-cut cohorts there, using standard tools.
- The enclave releases only privacy-safe, aggregated results, then wipes the data from memory.
The operational difference is the whole story: federated learning asks each site to run compute; confidential computing asks each site only to encrypt and upload.
The case for federated learning
If your sites already have harmonized data and active local compute, federated learning is often the pragmatic, well-trodden choice.
In mature networks like DARWIN EU and EHDEN, the databases are already mapped to a common data model (OMOP), meaning the hard harmonization work is done, and the sites have the infrastructure and staff to run standard analytical packages. In that world, federated analytics fits cleanly: it respects the existing setup, moves no data, and lets a coordinator distribute a pre-agreed analysis. Academic medical centers have done this successfully for years. If that describes your partners, you do not need anything more elaborate.
Where federated learning gets hard
The same approach struggles in newer or more mixed collaborations:
- The harmonization tax. Mapping a hospital’s database to a common model like OMOP is a large project, often 12 to 24 months per site. If your partners have not already done it, federated learning does not remove that cost; it just leaves it on each site’s plate before the study can start.
- Infrastructure burden on partners. Federated learning needs each site to host and maintain compute and run the pipelines. Many community hospitals and smaller registries cannot, which quietly excludes them and shrinks your statistical power.
- Little room to iterate. The analysis usually has to be agreed and locked across all sites in advance. When a data scientist wants to fix a model, re-cut a cohort, or explore a new question, that means another round of multi-site approval and redeployment. If you rarely know the final analysis up front, this is the constraint that hurts most.
Privacy and security: Two different threat models
Both approaches are a large step up from the default of pooling raw records in one place, and both replace administrative promises with a technical guarantee. The difference is what that guarantee rests on. Each has its own threat model, with one place it is genuinely exposed, and choosing well means comparing those two exposures, not chasing a “fully private” claim that no system can make.
- Federated learning. “The data never moves” is true, but it does not make the process automatically private. The model updates that do move can be reverse-engineered to reconstruct patient data, a risk first demonstrated as “deep leakage from gradients.” The standard defense is to add statistical noise to those updates (differential privacy), but the noise costs accuracy: in one heart-disease model, accuracy fell from about 99% to about 90% once differential privacy was applied. So federated learning is cleanest when your study does not depend on that defense, and more fragile when it does.
- Confidential computing. The data is protected while it is analyzed, but you are trusting the hardware vendor. Researchers have documented hardware-level attacks against TEEs, mostly subtle side channels, though they are difficult to execute against a production cloud deployment where an attacker has no physical access to the machine and the platform applies its own mitigations. The honest framing is that this is a real dependency, not a zero-risk guarantee.
The trade is, in plain terms: federated learning exposes you through what it shares, confidential computing through what it depends on.
How regulators see each one
The two approaches sit differently under the law, and that affects sign-off.
Under GDPR, federated learning usually makes the participating sites joint controllers, because they decide together what the model is for. Honoring a patient’s right to erasure is also genuinely hard, since their influence is baked into a trained model. Confidential computing keeps a cleaner split: hospitals stay controllers, the platform is a processor. Under the EU Court of Justice’s “relative approach” (Case C-413/23 P), data analyzed inside an attested enclave can be treated as effectively anonymous to the analyst and operator, because they have no realistic means to re-identify it. EHDS reinforces this by requiring secure processing environments for secondary research, which points directly at TEEs and data clean rooms.
In the US under HIPAA, federated learning keeps protected health information behind local firewalls but still needs differential privacy on what the model shares. Confidential computing can process protected health information inside a TEE under a business associate agreement, because encryption-in-use meets the security rule’s technical safeguards and only de-identified, aggregated output leaves the enclave.
How to evaluate the two for your study
Six criteria decide most multi-site RWE architecture choices:
- Where the raw data sits during analysis, and who could see it.
- What guarantees only approved analyses run: an administrative policy, or hardware.
- Cloud and stack neutrality: are you locked to one vendor.
- Burden on the data-holding sites: what you are asking partners to stand up.
- Room to iterate: can researchers explore, or must every query be pre-agreed.
- Regulatory fit: how cleanly it maps to GDPR, EHDS, and HIPAA.
The decision rule
Use federated learning when
- Your sites already have harmonized data (OMOP or FHIR) and the local compute and staff to run and maintain it, and
- The study is static: the analysis can be agreed up front and you do not need to iterate or harmonize messy data on the fly.
Use confidential computing when
- You need flexible, iterative analysis, exploratory work, or programmatic harmonization across diverse, un-harmonized datasets, or
- Your partners cannot or will not host and maintain local compute, or lack the staff for it.
The iCARE4CVD consortium illustrates both conditions. Led by Novo Nordisk and Maastricht University, 34 organizations across 12 countries needed to analyze data on more than a million cardiovascular patients across datasets that were not harmonized and with partners who could not run local compute. Using confidential computing data clean rooms, the consortium cut study setup from an estimated 24 months to around six.
If your collaboration is mature and pre-harmonized, federated learning is the lighter touch. If it is new, mixed, or still finding its questions, confidential computing removes the two things that most often stall these studies: the setup burden on partners and the inability to iterate.
How we made this comparison
This piece was written by Decentriq. Our read is grounded in building and running confidential-computing clean rooms for multi-party health collaborations, including iCARE4CVD, alongside published research on federated learning and TEE security. We provide confidential computing, and we have tried to give federated learning a fair account, because in pre-harmonized networks it is genuinely the right call.
Next steps
The architecture you choose shapes your timeline, your sign-off, and how many partners can take part. If you are designing a multi-site RWE study and want to work through which approach fits, visit our data clean room platform or talk to our team about your study architecture.
References
Whitepaper: Unlock the value of real-world healthcare data with confidential data clean rooms
As the amount of healthcare data from real-world settings grows, how can care providers and life sciences companies use this data to advance research and treatment while protecting sensitive patient information?
Related content




Subscribe to Decentriq
Stay connected with Decentriq. Receive email notifications about industry news and product updates.